· 4 min read
Maze Maze Mazeee
CTF Write-up
Quick Nav
BKSEC_training Hidden
Maze Maze Mazeee
Challenge Information
- Category: Web Exploitation
- Event: BKSEC training 2026
- Author: bksec
- Difficulty: Hidden
- Tags: #web #Script
1. Description
Warming up by escaping the maze is very common in CTF competitions.
2. Overview
Bài này round 1 sẽ cho một giao diện với các thẻ html đè lên nhau và yêu cầu người chơi phải tìm ra thẻ có đường dẫn đến page tiếp theo, round 2 sẽ bắt người chơi phải tìm flag trong các directory và thử nhiều flag để tìm ra flag thật.
3. Reconnaissance round 1
- Truy cập vào trang web và thấy dòng chữ
Are you robot.

-> nghĩ ngay đến /robots.txt
- Sau khi truy cập vào /robots.txt ta thấy được một đoạn base64 encode như sau:

-> decode base64 ta được: /pages/page-1-Tombstone.html
- Truy cập vào đường dẫn trên ta sẽ thấy giao diện gồm nhiều thẻ html css xếp chồng lên nhau

- Nếu để thế này rất khó nhìn nên ta mở code lên đọc luôn
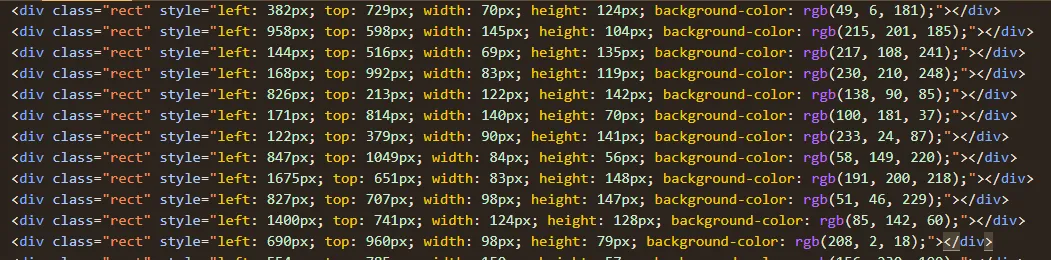
- Có rất nhiều thẻ như thế này, dự đoán sẽ có 1 thẻ nào đó chứa nội dung
-> Ctrl + F search
<athử xem sao
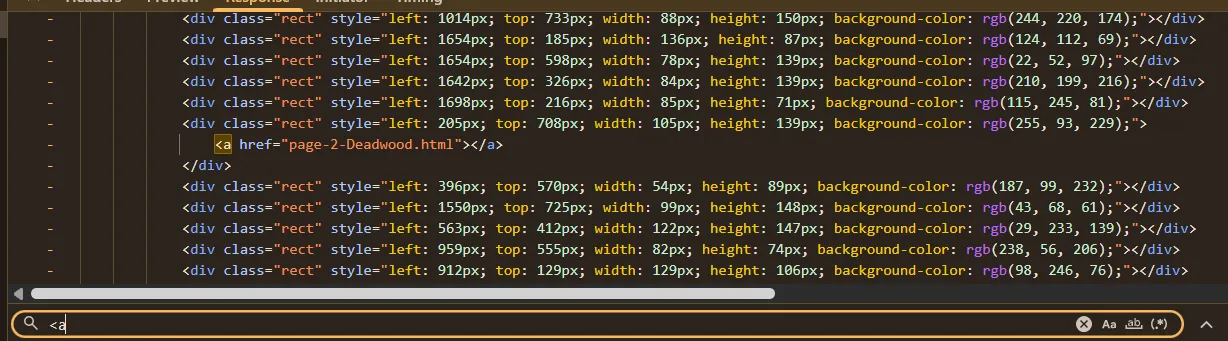
- Đã tìm thấy đường dẫn đến page tiếp theo, copy paste vào url để đi tiếp

- Lần này cũng tương tự, dự đoán với dạng bài này sẽ có rất nhiều page -> viết script để tự động hóa việc khai thác
4. Exploitation round 1
- Ta sẽ viết script sao cho tự động hóa việc tìm kiếm nội dung sau đó gán thẳng vào url để đi đến trang tiếp theo rồi lại tiếp tục lặp lại quy trình đó cho đến khi không thể tìm thấy nữa.
- Python script:
import requests
from bs4 import BeautifulSoup
url = "http://103.77.175.40:8031/pages/page-1-Tombstone.html"
base_url = "http://103.77.175.40:8031/pages/"
while True:
try:
print(f"{url}")
response = requests.get(url, timeout=5)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Tìm thẻ <a> đầu tiên có thuộc tính href
next_tag = soup.find('a', href=True)
if next_tag:
href = next_tag['href']
# Cập nhật URL mới
if href.startswith('page'):
url = base_url + href
else:
print("end")
break
except Exception as e:
print(f"Lỗi xảy ra: {e}")
break- Đến trang thứ 101 là kết thúc

- Trang cuối là thông báo đã vượt qua round 1 và chuyển sang round 2
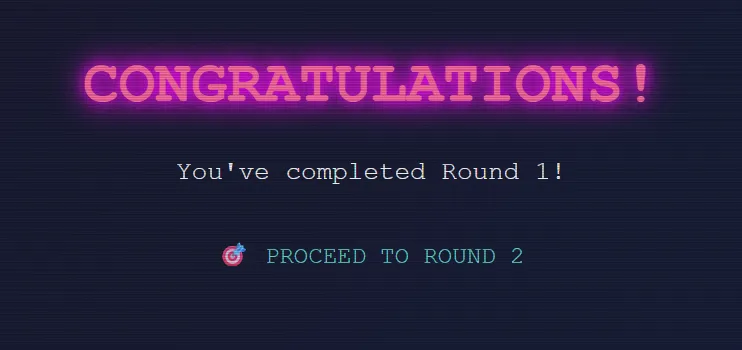
5. Reconnaissance round 2
- Truy cập vào
PROCEED TO ROUND 2ta sẽ thấy giao diện gồm các thư mục và mỗi thư mục lại có những thư mục con và các tệp nội dung đi kèm:

-> ta cũng sẽ viết script để khai thác round này
6. Exploitation round 2
- Script ở round này sẽ dùng BFS quét toàn bộ file để tìm flag:
import requests
from bs4 import BeautifulSoup
import urllib.parse
start_url = "http://103.77.175.40:8031/round2_qncdl1248dbsl/"
visited = set()
results = []
def bfs(url):
normalized_url = url.rstrip('/')
if normalized_url in visited:
return False
print(url)
visited.add(normalized_url)
try:
response = requests.get(url, timeout=5)
response.raise_for_status()
if "BKSEC" in response.text:
print("có flag")
results.append(response.text.strip())
soup = BeautifulSoup(response.text, 'html.parser')
links = soup.find_all('a')
for link in links:
href = link.get('href')
# Loại bỏ link điều hướng cơ bản
if not href or href in ["../", "./", "/"] or href.startswith("?"):
continue
# Tạo URL đầy đủ
next_url = urllib.parse.urljoin(url, href)
# Chỉ đi tiếp nếu URL thuộc cùng domain và cùng path gốc của Round 2
if next_url.startswith(start_url):
if bfs(next_url):
return True
except Exception as e:
return False
return False
bfs(start_url)
for item in results:
print(item)Kết quả:
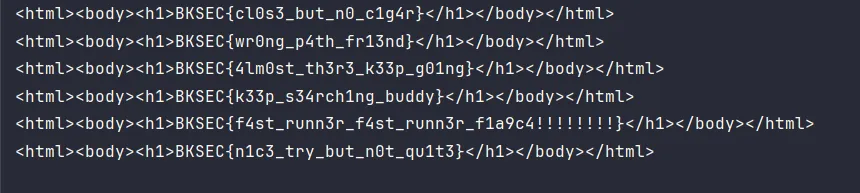
-> Thử từng flag để lấy flag thật